Publications
Authored research papers accepted, presented, and published in peer-reviewed international research conferences and journals with prestigious organizations including Scientific Reports (by Springer Nature) and IEEE Access (by IEEE); and also have served as a Peer reviewer for international research conferences.
Journal Research Papers

An Integrated TOPSIS and ARAS Method Multi-Criteria Decision-Making Approach for Optimizing Investment Portfolios Using Goal Programming and Genetic Algorithm Model
Scientific Reports | Springer Nature | IF = 3.9, 5th most cited journal in the world
Paper Published in October 2025
Enhancing Brain Tumor Diagnosis with Ensemble Deep Learning and Optimizer Tuning on MRI Data
Scientific Reports | Springer Nature | IF = 3.9, 5th most cited journal in the world
Paper Revision Submitted, Under Final Review

Pathological Speech Synthesis: A Framework and Performance Analysis
IEEE Access | IEEE | IF = 3.6
Paper Accepted, Revision Under Progress by Authors
IEEE Conference Papers
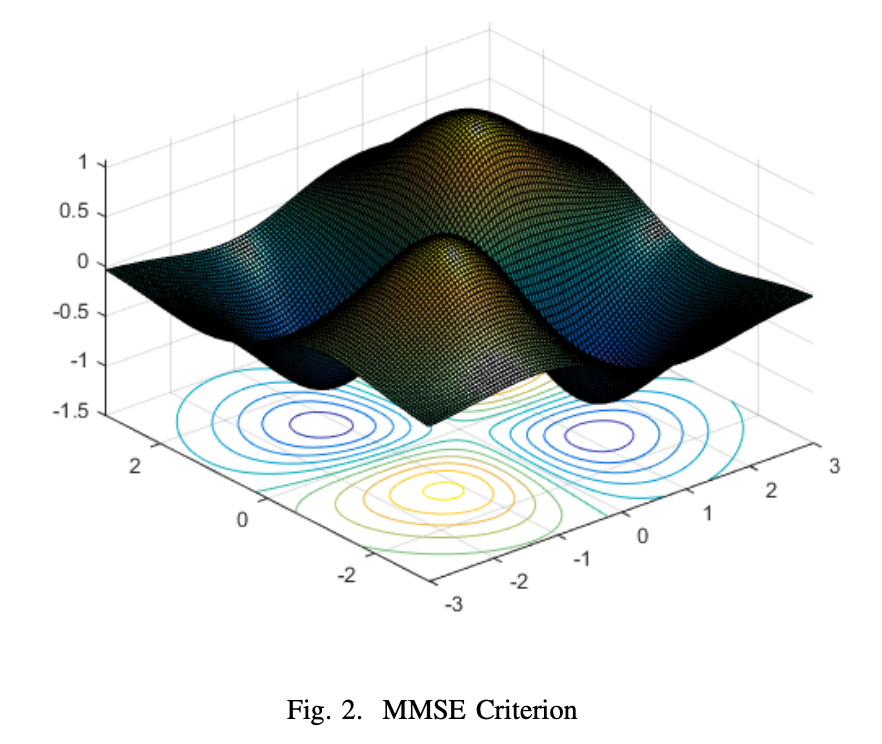
Harnessing Kernel Tricks for NonLinear Problem Solving: SVM Applications
IRASET 2025 | 2025 5th International Conference on Innovative Research in Applied Science, Engineering and Technology | Fez', Morocco
Paper Accepted, Presented in May 2025; and Published in May 2025
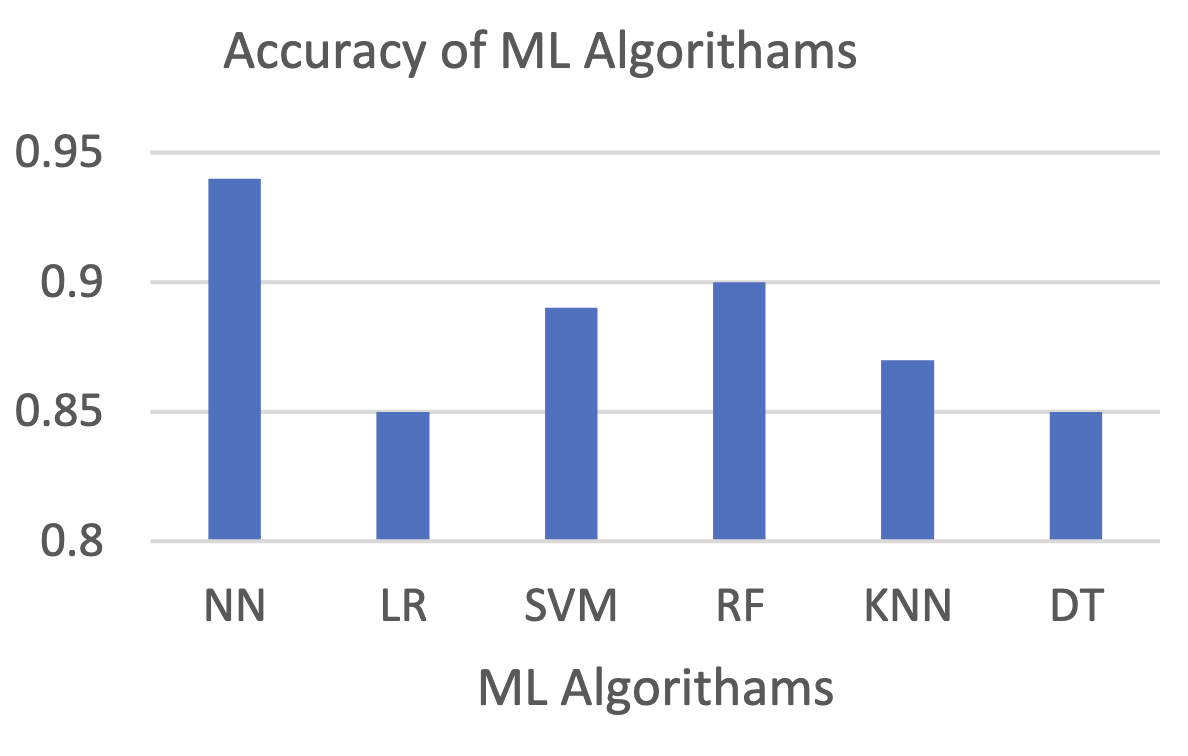
Detection of Nanoparticles with Machine Learning Technique: Evaluation of algorithm performance
ICSIT 2025 | IEEE 2025 International Conference on Sustainability, Innovation and Technology | Maharashtra, India
Paper Accepted; Presented in Aug 2025; and Published in December 2025
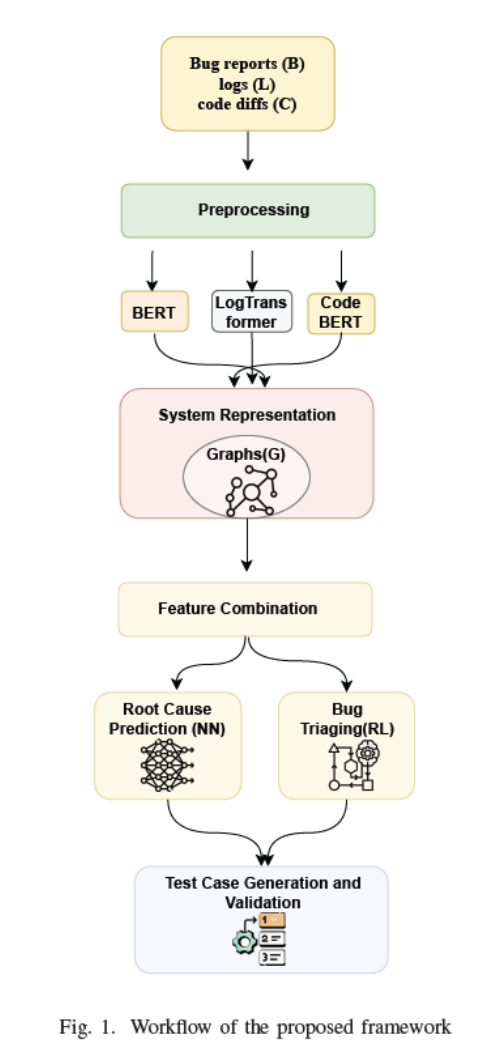
Integrating LLMs for Automated Bug Triaging and Root Cause Localization in Software Systems
AIBThings 2025 | 3rd IEEE International Conference on Artificial Intelligence, Blockchain and Internet of Things | Central Michigan University (CMU), Michigan, USA
Paper Accepted; Presented in Sept 2025; and Published in December 2025
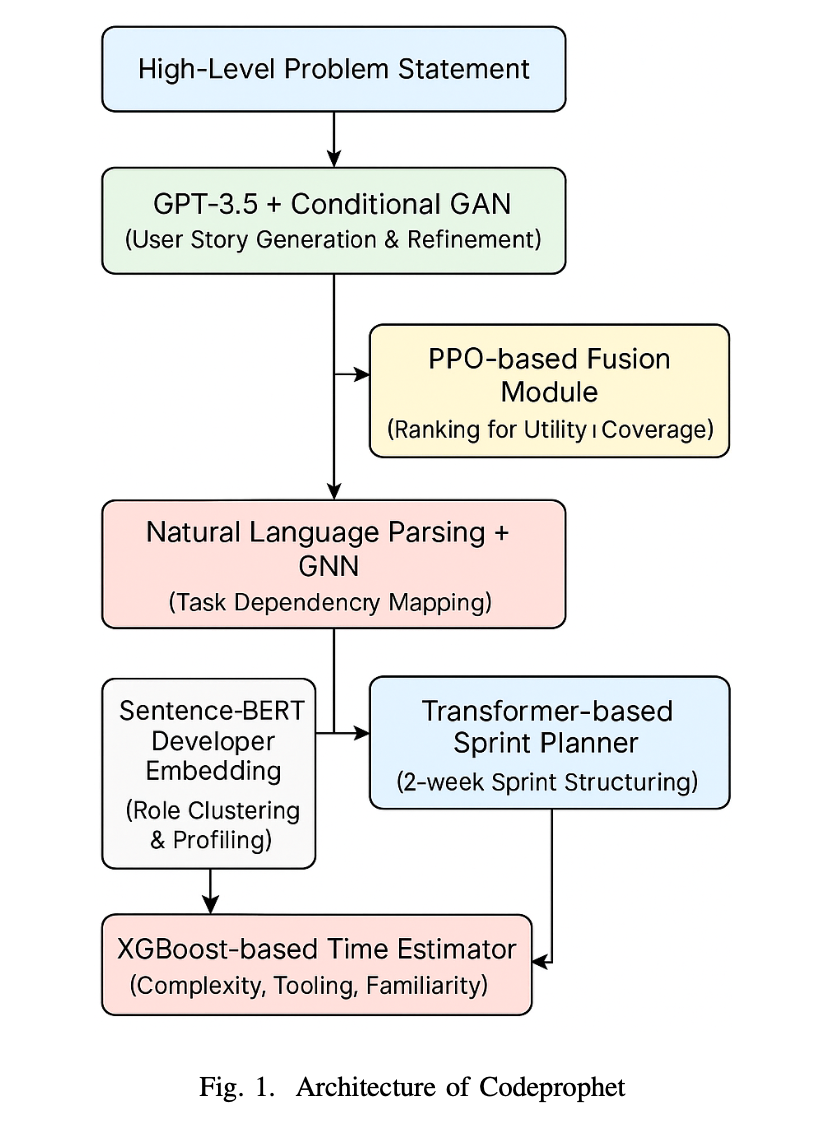
CodeProphet: A Predictive LLM Based Framework for Proactive Software Development Planning
AIBThings 2025 | 3rd IEEE International Conference on Artificial Intelligence, Blockchain and Internet of Things | Central Michigan University (CMU), Michigan, USA
Paper Accepted Presented in Sept 2025; and Published in December 2025
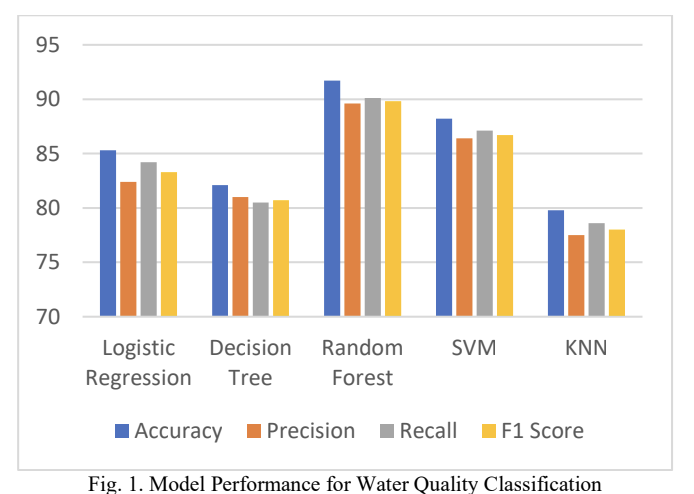
Prediction of Water quality using Machine Learning and Artificial Intelligence Techniques
ISCON 2025 | IEEE 2025 International Conference on Information Systems and Computer Networks | Mathura, Uttar Pradesh, India
Paper Accepted Presented in Sept 2025; and Published in January 2026